
Monday morning, nine o’clock, inbox overflowing with PDFs. A dividend notice here, a custodian feed there, an invoice that missed the cutoff last week. You could treat the pile like firewood—stack it neatly and chip away all afternoon—or you could let software do the lifting. Today’s back-office platforms behave like tireless interns: they read bank and broker feeds as they land, pluck totals from scanned invoices, and even log into stubborn portals when no API exists. Every clean line item flows straight into a unified ledger, so by the time you refill your coffee the books already match the market.
That is the short answer. Automation—built from feed networks, smart capture, and lightweight bots—turns data entry into a background hum instead of the day’s main event. The deep dive that follows breaks down the moving parts, from selecting a feed provider to choosing between cloud, on-prem, or a hybrid home for your new digital workforce.
Meet Your Automated Back Office
Family offices, fund administrators, and investment funds often grapple with large volumes of financial records spread across multiple systems. Traditionally, staff have entered and reconciled data manually, an approach that is slow and error-prone. This manual data entry remains widespread in finance and leads to frequent errors, inefficiencies, and reporting delays. For example, copying transactions from various bank platforms into spreadsheets can consume entire workdays and still risk mistakes.
The challenge is clear: how can organizations handling complex portfolios reduce these operational bottlenecks while staying compliant with strict financial regulations? Modern technology offers answers. Solutions like Robotic Process Automation (RPA) and system integration via APIs promise to automate data flows between portfolio-management systems, accounting platforms, custodians, and other tools. These approaches can eliminate repetitive work and improve accuracy. Additionally, firms must decide whether to deploy these solutions on cloud, on-premises, or hybrid infrastructures to balance scalability with security.
This report provides a structured overview of how to streamline large-scale financial data entry, examining RPA and API-based integrations, hybrid deployment options, and best practices for building scalable, accurate data pipelines.
Key Data Entry Challenges
Fragmented Data Sources
A typical investment organization uses disparate systems for accounting, trading, client reporting, banking, and more. Consolidating data from these siloed sources is daunting. Family offices, for instance, aggregate data from multiple banks, portfolios, and spreadsheets—often manually. Without integration, staff perform “hands-on-keyboard” work to re-key or copy data between systems. This fragmentation not only consumes time but also makes it hard to get a single source of truth for financial reporting.
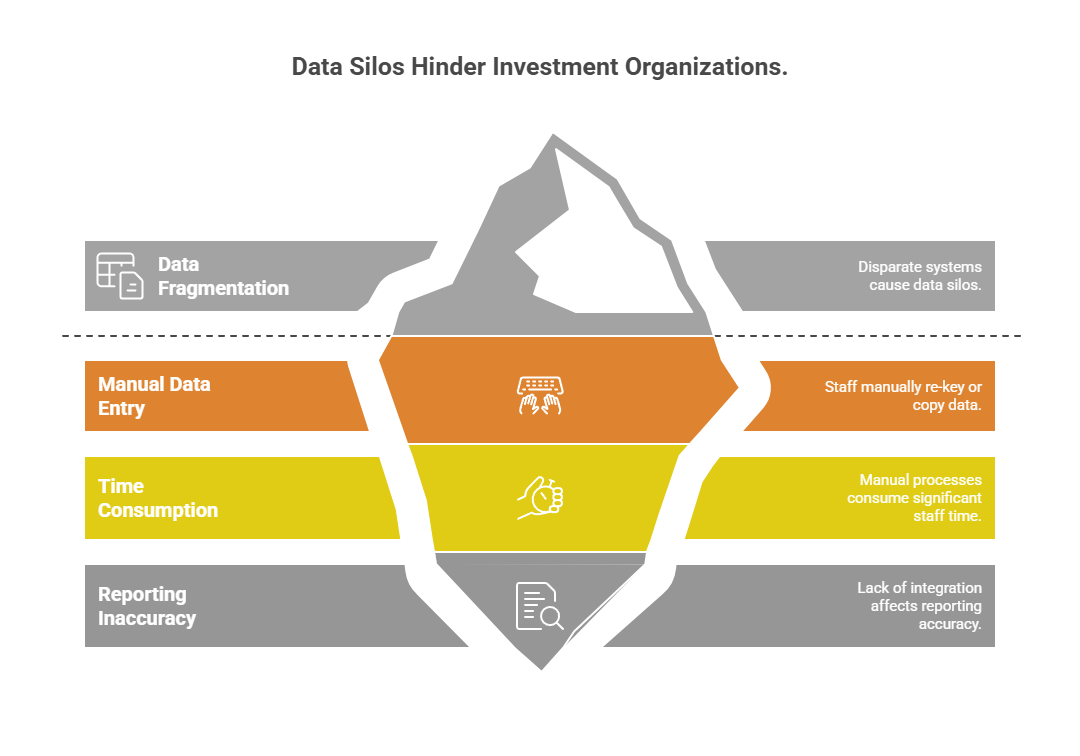
Operational Bottlenecks
Manual processes do not scale well. If the volume of transactions or accounts doubles, a team’s workload doubles in turn, delaying reporting and analysis. In one illustration, a family-office team spent nearly a full day consolidating transactions from multiple custodians; with automation, the same task took mere minutes. Human-driven processes also introduce delays for approvals and reconciliations, which can slow decision-making in fast-paced markets.

Regulatory Compliance and Data Security
Financial records are subject to strict regulations on privacy, auditability, and accuracy. Manual handling of data can introduce compliance risks—for example, staff might share login credentials or store sensitive data insecurely in spreadsheets. Firms must ensure data integrity and maintain audit trails to satisfy regulators. Any automation or integration solution must support these requirements (e.g., enforcing access controls and maintaining logs) to be viable in a heavily regulated environment.
Given these challenges, organizations are turning to automation and smarter system design to simplify data entry while mitigating errors and compliance risks. Two main approaches have gained traction: using RPA bots to mimic human data-entry tasks and building direct system integrations (often via APIs) for straight-through data processing. Each approach has distinct advantages and considerations.
Robotic Process Automation (RPA) Solutions
RPA involves software “bots” that emulate human actions in software interfaces. Think of an RPA bot as a virtual clerk: it can click buttons, copy-paste information, fill forms, or trigger reports just like a person, but faster and without fatigue. This makes RPA a powerful tool for automating data entry in finance. Common use cases include downloading monthly bank statements, entering invoice details into accounting systems, reconciling account balances, and moving data from emails or PDF reports into databases. These routine, rules-based tasks are ideal for RPA, as bots can follow the same steps consistently 24/7.

One key benefit of RPA is that it works on top of existing systems without requiring deep integration. Even if a legacy portfolio system has no modern API, an RPA bot can log in and input or extract data through the user interface. This makes RPA a quick solution when IT integration is not immediately feasible. There are many low-code RPA tools that allow teams to record their actions and rapidly deploy a bot, lowering the barrier to adoption. As a result, RPA can deliver rapid ROI—organizations have reported eliminating over 70 percent of manual data-entry work by implementing RPA bots for end-to-end processes. In financial operations, RPA has been used to aggregate data from “disparate accounting, operational, and reporting systems,” performing validation and formatting along the way. This capability to handle both structured and unstructured data means RPA can bridge fragmented data sources effectively.
However, RPA is not a silver bullet for every scenario. Because RPA bots mimic the user interface, they are sensitive to changes in applications—a minor software update or a moved button can cause a bot to fail if not adjusted. Maintenance and governance of RPA deployments are critical to ensure reliability over time. Additionally, RPA typically works sequentially (one bot performing one task at a time, albeit quickly). Scaling out to very large volumes might require deploying multiple bots and orchestrating them, which adds complexity. In contrast, direct system integrations can handle large data throughput more elegantly. RPA should therefore be viewed as a complement or quick fix, especially suited for processes without available APIs or for pilot automation projects. When possible, combining RPA with other integration methods (or upgrading to API-based flows) yields the best long-term resilience.
System Integration and API-Based Approaches
System integration refers to connecting software platforms so they exchange data automatically, without human intervention. Modern financial software often provides Application Programming Interfaces (APIs)—defined channels for sending and receiving data. By writing integration scripts or using integration middleware, firms can enable straight-through processing: for example, trade data from a portfolio-management system can automatically flow into the general ledger, or bank transaction feeds can sync into an internal database in real time. Automated integration creates a seamless, scheduled or real-time data exchange between internal systems and external sources. In practical terms, a fund’s central repository can be directly updated by custodians, market-data providers, CRM systems, and more, with no spreadsheets in between.
The advantages of API-based integration are significant. Data travels in a structured format from system to system, reducing the chance of transcription errors. Integration can fetch far more granular data than what a human sees on screen, enabling richer analysis. For instance, an API could pull not only a transaction’s amount and date but also metadata like instrument identifiers, exchange rates, or timestamps that might not be visible in a UI. This granularity lets firms apply precise rules for processing and validation of financial data. Efficiency is another benefit—a well-built API pipeline can process thousands of records in seconds, far outperforming any manual or RPA-based workflow. Integration also supports complex transformations: data can be consolidated, enriched, and fed into reports or dashboards automatically, providing up-to-the-minute insights for decision-makers.
That said, pursuing system integration comes with its own challenges. Development effort and expertise are required—setting up API connections and maintaining them demands software skills. Many family offices or smaller funds lack in-house IT capabilities, which has historically been a barrier. Legacy systems may not have readily available APIs; in such cases, firms resort to file-based transfers (CSV exports, SFTP uploads) as a form of integration. These are effective but may operate in batch cycles (e.g., nightly uploads) rather than real-time. Additionally, integrating multiple sources means dealing with different data formats and standards. Data mapping and transformation logic must be carefully designed so that, say, the security codes or account identifiers from one system correctly match those in another. According to a recent study, nearly half of IT decision-makers find it difficult to integrate data across different systems, underscoring the importance of planning and tool selection for such projects.
In spite of these hurdles, API-centric integration is often the end goal for scalable architecture. It provides a durable, transparent data pipeline. Many financial firms use hybrid approaches: starting with RPA for quick wins and then gradually implementing direct integrations for core systems. Some integration platforms (middleware or iPaaS solutions) even combine the two, offering RPA modules alongside API connectors. This leads us to a direct comparison of RPA vs. API strategies.
| RPA | API-Based Integration | |
|---|---|---|
| Speed to deploy | Very fast; low-code recording | Moderate; requires development |
| System requirements | Works with any UI | Needs API access |
| Scalability | Limited by bot instances | High throughput, real-time |
| Maintenance | Sensitive to UI changes | More robust once built |
| Use cases | Quick fixes, legacy apps | Core data pipelines, high volume |
Cloud vs. On-Premises Deployment
When implementing automation solutions, firms must decide where to host these tools and data pipelines. Both cloud-based and on-premises deployments (or a mix of both) are common in the finance industry, each with pros and cons.
Cloud Solutions
Hosting RPA platforms or integration middleware in the cloud can dramatically reduce deployment time and upfront cost. Cloud RPA services allow organizations to start automating within days by providing pre-built environments and bots ready to use. Cloud infrastructure scales elastically—if data volumes spike or more processing power is needed, resources can be ramped up on demand without procuring new hardware. This flexibility often makes cloud more cost-efficient, especially when automation needs grow gradually. Another benefit is managed maintenance: cloud providers handle updates, security patches, and 24/7 uptime, which would be costly to replicate in-house. However, finance professionals must consider data security and compliance when using cloud services. Sensitive financial records might be subject to data residency laws or internal policies that limit cloud usage. Reputable cloud solutions address this with encryption and compliance certifications, but due diligence is required.
On-Premises Solutions
Deploying automation tools on-premises (within a firm’s own data center or servers) gives organizations maximum control. Data stays behind corporate firewalls, which can simplify compliance with regulations that demand strict data sovereignty. For latency-sensitive tasks—say, a trading system that needs millisecond updates—on-prem deployments located close to the data source can minimize network delays. Dedicated on-prem resources also avoid the performance variability that sometimes comes with multi-tenant cloud platforms. The trade-off is cost and agility: building and maintaining an on-premises automation environment that runs reliably 24/7 can be extremely expensive. Firms must invest in servers, networking, and possibly redundant setups for high availability. Scaling up may be slower, as it involves purchasing and configuring new hardware or VMs. Additionally, the responsibility for security updates and system maintenance lies entirely with the firm’s IT team.
Hybrid Deployment
Many financial institutions adopt a hybrid approach, combining on-premises and cloud elements to get the best of both worlds. A hybrid deployment might involve keeping sensitive data processing on-premises for compliance, while leveraging the cloud for heavy analytics or as a backup and disaster-recovery site. Hybrid integration platforms allow data to be processed where it resides—whether locally or in the cloud—thus reducing the need to move sensitive information and lowering risk. This model can enhance compliance by enabling in-place data processing that respects geographic regulations (e.g., keeping EU client data within EU servers to satisfy GDPR). Performance can also improve: processing data near its source (on-prem or at the edge) cuts down on latency and network transfers. Cost optimization is another driver for hybrid strategies—organizations can avoid cloud-egress fees by filtering and aggregating data on-premises, sending only necessary results to the cloud. In summary, hybrid deployments offer flexibility: critical workloads run on the environment best suited to them (for example, on-prem for low-latency feeds, cloud for scalable storage or compute), all under a unified integration architecture.
In deciding between cloud, on-premises, or hybrid, firms should evaluate their regulatory constraints, transaction volumes, and IT capabilities. Often, new projects start in the cloud for speed, then certain components are brought on-premises as needed for compliance. Modern integration solutions (including many RPA and data-pipeline tools) support this flexibility, allowing companies to switch or mix deployment models as their needs evolve.
Best Practices for Scalable and Accurate Data Pipelines
Standardize and Validate Data
When aggregating data from fragmented sources, enforce common data formats and validation rules at the point of entry. Nearly half of IT leaders cite data incompatibility as a major integration hurdle, so establishing a consistent data schema is crucial. Use automated checks to reject or flag anomalies (e.g., out-of-balance entries, invalid account codes) before they pollute the system. Gartner estimates poor data quality costs organizations millions annually, reflecting the high stakes of accuracy.
- Implement Strong Controls and Security
Every step of a financial data pipeline should be secure and auditable. Best practices include encrypting data in transit and at rest, using role-based access controls to limit who or what can alter data, and maintaining detailed audit logs. These controls not only protect sensitive information but also create an audit trail for compliance purposes. Automation tools can assist by automatically recording all transactions and transformations performed by bots or integration jobs. - Monitoring and Error Handling
Design the system with monitoring in mind. Integrated dashboards or alerts should track data flows and notify the team of any failures or exceptions in real time. For instance, if a custodian’s API is down or an RPA bot encounters an unexpected screen, the system should log the error and alert IT staff. Incorporate retry mechanisms and fallbacks (such as switching to a backup source or queuing transactions for later) so that temporary glitches do not derail the entire pipeline. Having the ability to manually intervene—for example, to rerun a failed job or adjust a parameter—is also important for operational resilience. - Gradual Implementation and Testing
When overhauling data-entry processes, take an incremental approach. Start by automating high-impact, low-risk tasks to gain confidence and demonstrate quick wins (for example, automating data import from a frequently used bank). Rigorously test each integration with a subset of data and run it in parallel with existing manual processes until results align. This phased rollout helps identify issues early and allows staff to adapt to new workflows. Documentation and training should accompany each new automation so that both IT and finance teams understand how data is flowing and how to troubleshoot if needed. - Collaboration Between IT and Finance
A scalable data pipeline sits at the intersection of technology and financial domain knowledge. Involve both IT professionals and finance/end-user stakeholders in the design. IT can ensure the architecture is sound (covering aspects like database performance, network capacity, and failover planning), while finance teams can validate that the business logic (calculations, mappings, report outputs) is accurate and meets regulatory standards. If in-house expertise is lacking, consider partnering with specialists or consultants who have experience in financial data automation. Their insight can help bridge technical gaps and incorporate industry best practices from day one.
By following these practices, organizations create data pipelines that are not only efficient but also trustworthy. The goal is to have a system where data moves automatically from source to destination with minimal manual touchpoints, yet every transaction is recorded, verified, and secure. This allows firms to scale up their operations (onboarding more clients, processing more trades) without a commensurate increase in data-entry workload or risk.
Conclusion
For family offices, fund administrators, and investment funds, simplifying large-scale data entry is a strategic imperative in today’s data-driven finance environment. Automation is the key—whether through RPA bots that can rapidly relieve teams of repetitive tasks, or through direct system integrations that seamlessly connect databases and applications. Each approach has its role: RPA offers a quick path to efficiency, while API-based integrations provide a sturdy backbone for long-term scalability. Moreover, the choice of deployment (cloud, on-premises, or hybrid) should align with the organization’s compliance obligations and performance needs. Many firms find that a hybrid model delivers the needed flexibility, letting them keep sensitive processes in-house while leveraging the cloud for elasticity and speed.
Ultimately, success in this arena comes from a blend of the right technology and good governance. Automating large-scale financial data entry is not a one-off project but an evolving program—one that requires continuous monitoring, maintenance, and adaptation to new regulations or business requirements. By prioritizing data quality, security, and clear process design, financial organizations can build scalable data pipelines that significantly reduce manual work and errors. The result is a more efficient operation that frees up human talent for higher-value analysis and decision-making, all while ensuring that the integrity and timeliness of financial information are never compromised.



